Как сделать апроксимацию в excel
Аппроксимация в Excel
 (Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
(Обратите внимание на дополнительный раздел от 04.06.2017 в конце статьи.)
Учет и контроль! Те, кому за 40 должны хорошо помнить этот лозунг из эпохи построения социализма и коммунизма в нашей стране.
Но без хорошо налаженного учета невозможно эффективное функционирование ни страны, ни области, ни предприятия, ни домашнего хозяйства при любой общественно-экономической формации общества! Для составления прогнозов и планов деятельности и развития необходимы исходные данные. Где их брать? Только один достоверный источник – это ваши статистические учетные данные предыдущих периодов времени.
Учитывать результаты своей деятельности, собирать и записывать информацию, обрабатывать и анализировать данные, применять результаты анализа для принятия правильных решений в будущем должен, в моем понимании, каждый здравомыслящий человек. Это есть ничто иное, как накопление и рациональное использование своего жизненного опыта. Если не вести учет важных данных, то вы через определенный период времени их забудете и, начав заниматься этими вопросами вновь, вы опять наделаете те же ошибки, что делали, когда впервые этим занимались.
«Мы, помню, 5 лет назад изготавливали до 1000 штук таких изделий в месяц, а сейчас и 700 еле-еле собираем!». Открываем статистику и видим, что 5 лет назад и 500 штук не изготавливали…
«Во сколько обходится километр пробега твоего автомобиля с учетом всех затрат?» Открываем статистику – 6 руб./км. Поездка на работу – 107 рублей. Дешевле, чем на такси (180 рублей) более чем в полтора раза. А бывали времена, когда на такси было дешевле…
«Сколько времени требуется для изготовления металлоконструкций уголковой башни связи высотой 50 м?» Открываем статистику – и через 5 минут готов ответ…
«Сколько будет стоить ремонт комнаты в квартире?» Поднимаем старые записи, делаем поправку на инфляцию за прошедшие годы, учитываем, что в прошлый раз купили материалы на 10% дешевле рыночной цены и – ориентировочную стоимость мы уже знаем…
Ведя учет своей профессиональной деятельности, вы всегда будете готовы ответить на вопрос начальника: «Когда. ». Ведя учет домашнего хозяйства, легче спланировать расходы на крупные покупки, отдых и прочие расходы в будущем, приняв соответствующие меры по дополнительному заработку или по сокращению необязательных расходов сегодня.
В этой статье я на простом примере покажу, как можно обрабатывать собранные статистические данные в Excel для возможности дальнейшего использования при прогнозировании будущих периодов.
Аппроксимация в Excel статистических данных аналитической функцией.
Производственный участок изготавливает строительные металлоконструкции из листового и профильного металлопроката. Участок работает стабильно, заказы однотипные, численность рабочих колеблется незначительно. Есть данные о выпуске продукции за предыдущие 12 месяцев и о количестве переработанного в эти периоды времени металлопроката по группам: листы, двутавры, швеллеры, уголки, трубы круглые, профили прямоугольного сечения, круглый прокат. После предварительного анализа исходных данных возникло предположение, что суммарный месячный выпуск металлоконструкций существенно зависит от количества уголков в заказах. Проверим это предположение.
Прежде всего, несколько слов об аппроксимации. Мы будем искать закон – аналитическую функцию, то есть функцию, заданную уравнением, которое лучше других описывает зависимость общего выпуска металлоконструкций от количества уголкового проката в выполненных заказах. Это и есть аппроксимация, а найденное уравнение называется аппроксимирующей функцией для исходной функции, заданной в виде таблицы.
1. Включаем Excel и помещаем на лист таблицу с данными статистики.
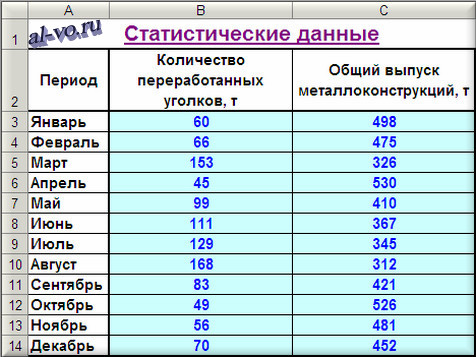
2. Далее строим и форматируем точечную диаграмму, в которой по оси X задаем значения аргумента – количество переработанных уголков в тоннах. По оси Y откладываем значения исходной функции – общий выпуск металлоконструкций в месяц, заданные таблицей.
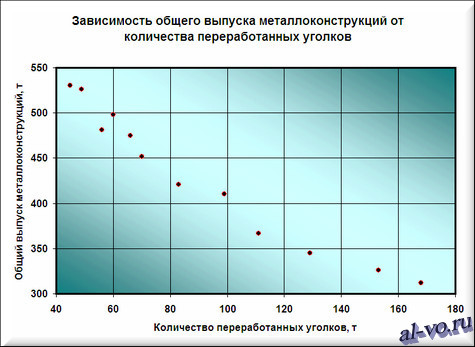
О том, как построить подобную диаграмму, подробно рассказано в статье «Как строить графики в Excel?».
3. «Наводим» мышь на любую из точек на графике и щелчком правой кнопки вызываем контекстное меню (как говорит один мой хороший товарищ — работая в незнакомой программе, когда не знаешь, что делать, чаще щелкай правой кнопкой мыши…). В выпавшем меню выбираем «Добавить линию тренда…».
4. В появившемся окне «Линия тренда» на вкладке «Тип» выбираем «Линейная».
5. Далее на вкладке «Параметры» ставим 2 галочки и нажимаем «ОК».
6. На графике появилась прямая линия, аппроксимирующая нашу табличную зависимость.
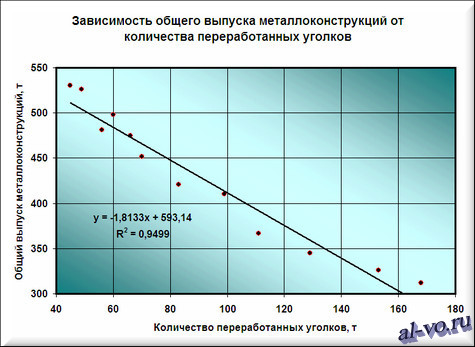
Мы видим кроме самой линии уравнение этой линии и, главное, мы видим значение параметра R 2 – величины достоверности аппроксимации! Чем ближе его значение к 1, тем наиболее точно выбранная функция аппроксимирует табличные данные!
7. Строим линии тренда, используя степенную, логарифмическую, экспоненциальную и полиномиальную аппроксимации по аналогии с тем, как мы строили линейную линию тренда.
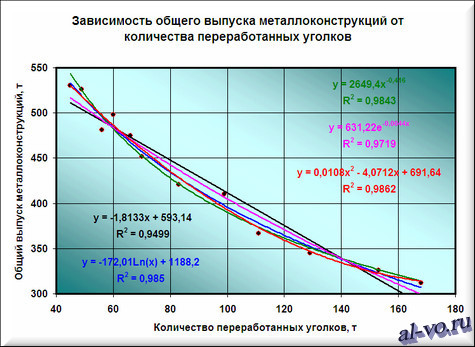
Лучше всех из выбранных функций аппроксимирует наши данные полином второй степени, у него максимальный коэффициент достоверности R 2 .
Однако хочу вас предостеречь! Если вы возьмете полиномы более высоких степеней, то, возможно, получите еще лучшие результаты, но кривые будут иметь замысловатый вид…. Здесь важно понимать, что мы ищем функцию, которая имеет физический смысл. Что это означает? Это означает, что нам нужна аппроксимирующая функция, которая будет выдавать адекватные результаты не только внутри рассматриваемого диапазона значений X, но и за его пределами, то есть ответит на вопрос: «Какой будет выпуск металлоконструкций при количестве переработанных за месяц уголков меньше 45 и больше 168 тонн!» Поэтому я не рекомендую увлекаться полиномами высоких степеней, да и параболу (полином второй степени) выбирать осторожно!
Итак, нам необходимо выбрать функцию, которая не только хорошо интерполирует табличные данные в пределах диапазона значений X=45…168, но и допускает адекватную экстраполяцию за пределами этого диапазона. Я выбираю в данном случае логарифмическую функцию, хотя можно выбрать и линейную, как наиболее простую. В рассматриваемом примере при выборе линейной аппроксимации в excel ошибки будут больше, чем при выборе логарифмической, но не на много.
8. Удаляем все линии тренда с поля диаграммы, кроме логарифмической функции. Для этого щелкаем правой кнопкой мыши по ненужным линиям и в выпавшем контекстном меню выбираем «Очистить».
9. В завершении добавим к точкам табличных данных планки погрешностей. Для этого правой кнопкой мыши щелкаем на любой из точек на графике и в контекстном меню выбираем «Формат рядов данных…» и настраиваем данные на вкладке «Y-погрешности» так, как на рисунке ниже.
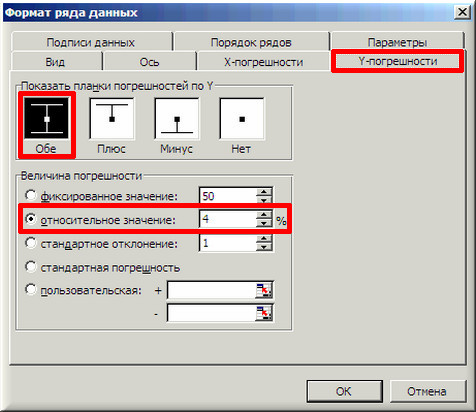
10. Затем щелкаем по любой из линий диапазонов погрешностей правой кнопкой мыши, выбираем в контекстном меню «Формат полос погрешностей…» и в окне «Формат планок погрешностей» на вкладке «Вид» настраиваем цвет и толщину линий.
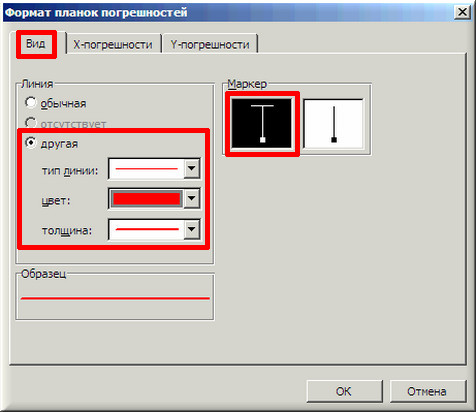
Аналогичным образом форматируются любые другие объекты диаграммы в Excel!
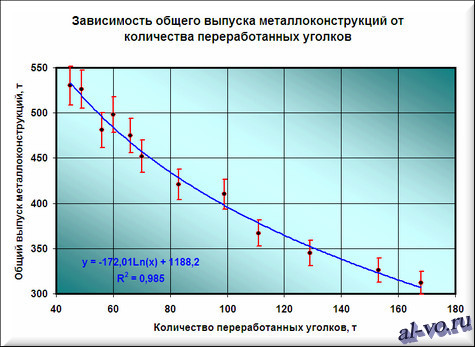
Окончательный результат диаграммы представлен на следующем снимке экрана.
Итоги.
Результатом всех предыдущих действий стала полученная формула аппроксимирующей функции y=-172,01*ln (x)+1188,2. Зная ее, и количество уголков в месячном наборе работ, можно с высокой степенью вероятности (±4% — смотри планки погрешностей) спрогнозировать общий выпуск металлоконструкций за месяц! Например, если в плане на месяц 140 тонн уголков, то общий выпуск, скорее всего, при прочих равных составит 338±14 тонн.
Для повышения достоверности аппроксимации статистических данных должно быть много. Двенадцать пар значений – это маловато.
Из практики скажу, что хорошим результатом следует считать нахождение аппроксимирующей функции с коэффициентом достоверности R 2 >0,87. Отличный результат – при R 2 >0,94.
На практике бывает трудно выделить один самый главный определяющий фактор (в нашем примере – масса переработанных за месяц уголков), но если постараться, то в каждой конкретной задаче его всегда можно найти! Конечно, общий выпуск продукции за месяц реально зависит от сотни факторов, для учета которых необходимы существенные трудозатраты нормировщиков и других специалистов. Только результат все равно будет приблизительным! Так стоит ли нести затраты, если есть гораздо более дешевое математическое моделирование!
В этой статье я лишь прикоснулся к верхушке айсберга под названием сбор, обработка и практическое использование статистических данных. О том удалось, или нет, мне расшевелить ваш интерес к этой теме, надеюсь узнать из комментариев и рейтинга статьи в поисковиках.
Затронутый вопрос аппроксимации функции одной переменной имеет широкое практическое применение в разных сферах жизни. Но гораздо большее применение имеет решение задачи аппроксимации функции нескольких независимых переменных…. Об этом и не только читайте в следующих статьях на блоге.
Подписывайтесь на анонсы статей в окне, расположенном в конце каждой статьи или в окне вверху страницы.
Не забывайте подтверждать подписку кликом по ссылке в письме, которое придет к вам на указанную почту (может прийти в папку «Спам»).
С интересом прочту Ваши комментарии, уважаемые читатели! Пишите!
P.S. (04.06.2017)
Высокоточная красивая замена табличных данных простым уравнением.
Вас не устраивают полученные точность аппроксимации (R 2 2 =0,9963.
Ошибка аппроксимации эксель. Как сделать апроксимацию в excel
Напомним, что регрессионный анализ это вид статистического анализа, используемый для прогнозирования. Регрессионный анализ позволяет оценить степень связи между переменными, предлагая механизм вычисления предполагаемого значения переменной из нескольких уже известных значений.
Линиями тренда можно дополнить ряды данных, представленные на ненормированных плоских диаграммах с областями, линейчатых диаграммах, гистограммах, графиках, биржевых, точечных и пузырьковых диаграммах. Использование линии тренда того или иного вида определяется типом данных. Нельзя дополнить линиями тренда ряды данных на объемных диаграммах, нормированных диаграммах, лепестковых диаграммах, круговых и кольцевых диаграммах.
Более ясно закономерность в развитии данных показывает сглаженная кривая. Она строится по точкам скользящего среднего, где под скользящим средним подразумевается последовательность средних чисел, каждое из которых вычислено по некоторому подмножеству ряда данных.
Добавление линии тренда или скользящего среднего к рядам данных
В Excel используются шесть различных видов линий тренда (аппроксимация и сглаживание), которые могут быть добавлены в диаграмму (рис. 18.11):
- Линейная аппроксимация (Linear) – это прямая линия, наилучшим образом описывающая набор данных. Уравнение прямой у=ах+Ь, где а – тангенс угла наклона, b – точка пересечения прямой с осью у. Линейная аппроксимация применяется для переменных, которые увеличиваются или убывают с постоянной скоростью.
- Логарифмическая аппроксимация (Logarithmic) хорошо описывает положительные, так и отрицательные величины, которые вначале быстро растут или убывают, а затем постепенно стабилизируется. Логарифмическая аппроксимация использует уравнение у=с* lnx+Ь, где с и b константы, In – натуральный логарифм.
- Полиномиальная аппроксимация (Polynomial) используется для описания величин, попеременно возрастающих и убывающих. Ее целесообразно применять для анализа большого набора данных нестабильной величины. Степень полинома определяется количеством экстремумов (максимумов и минимумов) кривой. Полином второй степени может описать только один максимум или минимум. Полином третьей степени имеет один или два экстремума. Полином четвертой степени может иметь не более трех экстремумов. Полиномиальная аппроксимация описывается уравнением y=a+ciXi+C2X2++Cigx18, где a, Cj-Cjg – константы. Требуемая степень полинома задается в поле Степень (рис.). Максимальная величина степени – 18.
- Степенная аппроксимация (Power) дает хорошие результаты, если зависимость, которая содержится в данных, характеризуется постоянной скоростью роста. Примером такой зависимости может служить график ускорения автомобиля. Если в данных имеются нулевые или отрицательные значения, использование степенного приближения невозможно. Степенная аппроксимация описывается уравнением у=а * хn, где а и n – константы.
- Экспоненциальную аппроксимацию (Exponential) следует использовать в том случае, если скорость изменения данных непрерывно возрастает. Однако для данных, которые содержат нулевые или отрицательные значения, этот вид приближения неприменим. Экспоненциальная аппроксимация описывается уравнением у= а ebx, где а и b – константы.
- Линейная фильтрация (Moving average) позволяет сгладить колебания данных и таким образом более наглядно показать характер зависимости. Такая линия тренда строится по определенному числу точек (она задается параметром Тонки (Period). Элементы данных усредняются, и полученный результат используется в качестве среднего значения для приближения. Так, если параметр Тонки равен 2, первая точка сглаживающей кривой определяется как среднее значение первых двух элементов данных, вторая точка – как среднее следующих двух элементов и так далее. Для расчета скользящего среднего используется уравнение у= (Aj+Aj_i++Aj_n+i)/n.
Добавление линии тренда к рядам данных
Для добавления линии тренда к рядам данных выполните следующие действия:
- выделите ряд данных, к которому нужно добавить линию тренда или скользящее среднее;
- выберите команду Добавить линию тренда (Add Trendline) в меню Диаграмма (Chart). На вкладке Тип (Type) выберите нужный тип регрессионной линии тренда или линии скользящего среднего (рис. 18.11);
- при выборе типа Полиномиальная (Polynomial) введите в поле Степень (Order) наибольшую степень для независимой переменной;
- при выборе типа Скользящее среднее (Moving Average) введите в поле Точки (Period) число точек, используемых для расчета скользящего среднего.
Рис. 18.11 . Выбор линии тренда
Microsoft Excel (также иногда называется Microsoft Office Excel) — программа для работы с электронными таблицами, созданная корпорацией Microsoft для Microsoft Windows, Windows NT и Mac OS. Она предоставляет возможности экономико-статистических расчетов, графические инструменты и, за исключением Excel 2008 под Mac OS X, язык макропрограммирования VBA (Visual Basic для приложений). Microsoft Excel входит в состав Microsoft Office и на сегодняшний день Excel является одним из наиболее популярных приложений в мире.
В MS Excel аппроксимация экспериментальных данных осуществляется путем построения их графика (x – отвлеченные величины) или точечного графика (x – имеет конкретные значения) с последующим подбором подходящей аппроксимирующей функции (линии тренда).
Возможны следующие варианты функций:
· Линейная – y=ax+b. Обычно применяется в простейших случаях, когда экспериментальные данные возрастают или убывают с постоянной скоростью.
· Полиномиальная – y=a 0 +a 1 x+a 2 x 2 +…+a n x n , где до шестого порядка включительно (n?6), a i – константы. Используется для описания экспериментальных данных, попеременно возрастающих и убывающих. Степень полинома определяется количеством экстремумов (максимумов или минимумов) кривой. Полином второй степени можно описать только один максимум или минимум, полином третьей степени может иметь один или два экстремума, четвертой степени – не более трех экстремумов и т.д.
· Логарифмическая – y=a·lnx+b, где a и b – константы, ln – функция натурального логарифма. Функция применяется для описания экспериментальных данных, которые вначале быстро растут или убывают, а затем постепенно стабилизируются.
· Степенная – y=b·x a , где a и b – константы. Аппроксимация степенной функцией используется для экспериментальных данных с постоянно увеличивающейся (или убывающей) скоростью роста. Данные не должны иметь нулевых или отрицательных значений.
· Экспоненциальная – y=b·e ax , a и b – константы, e – основание натурального логарифма. Применяется для описания экспериментальных данных, которые быстро растут или убывают, а затем постепенно стабилизируются. Часто ее использование вытекает из теоретических соображений.
Степень близости аппроксимации экспериментальных данных выбранной функцией оценивается коэффициентом детерминации (R 2). Таким образом, если есть несколько подходящих вариантов типов аппроксимирующих функций, можно выбрать функцию с большим коэффициентом детерминации (стремящимся к 1).
Аппроксимация экспериментальных данных в программе MathCAD
MathCAD — это специфический язык программирования, который позволяет облегчить решение математических уравнений. MathCAD — система компьютерной алгебры из класса систем автоматизированного проектирования, ориентированная на подготовку интерактивных документов с вычислениями и визуальным сопровождением, отличается легкостью использования и применения для коллективной работы. MathCAD идеально подходит для осуществления математического моделирования — осуществляя решение разного рода уравнений и создавая отчет о полученных результатах.
В MathCAD совсем немного типов данных по сравнению с универсальными языками программирования — всего три. Кратко охарактеризуем их (более детально они будут описаны позже).
Числа (как действительные, так и комплексные): все числа MathCAD хранит в одном формате (с плавающей точкой двойной точности), не разделяя их на целые и действительные. На одно число выделяется 64 бита. При этом десятичная часть не может превышать по длине 17 знаков, а порядок должен лежать между -307 и 307. Комплексные числа на уровне реализации представляют собой пару действительных чисел. При этом во многих видах расчетов число воспринимается как комплексное, даже если у него нет мнимой части. Описанные особенности чисел в MathCAD касаются только численных расчетов. При работе в символьном режиме совершенно другие уровни точности.
Строки: в общем случае любой текст, заключенный в кавычки. На практике строки используются в основном для задания сообщений об ошибках, возникших при работе программ на языке MathCAD.
Массивы: к ним относятся матрицы, векторы, тензоры, таблицы — любые упорядоченные последовательности элементов произвольного типа. К данным этого типа можно отнести и ранжированные переменные. В отдельную группу следует выделить так называемые размерные переменные, то есть единицы измерения, имеющие огромное значение в науке и технике. В MathCAD нет логического типа данных. Для обозначения истины и лжи логическими операторами и функциями используются числа — 0 и 1.
В MathCAD существует несколько функций, позволяющих выполнить регрессию с использованием зависимостей, наиболее часто встречающихся на практике. Таких функций в MathCAD всего шесть. Вот некоторые из них:
· expfit(vx,vy,vg) – регрессия экспоненциальной функцией y = a*e b*x +c.
· sinfit(vx,vy,vg) – регрессия синусоидальной функцией y = a*sin(x+b)+c.
· pwrfit(vx,vy,vg) – регрессия степенной функцией e = a*x b +c.
Перечисленные функции используют трехпараметрическую аппроксимирующую функцию, нелинейную по параметрам. При вычислении оптимальных значений трех параметров регрессионной функции по методу наименьших квадратов возникает необходимость в решении сложной системы из трех нелинейных уравнений. Такая система часто может иметь несколько решений. Поэтому в функциях MathCAD, которые проводят регрессию трехпараметрическими зависимостями, введен дополнительный аргумент vg. Данный аргумент – это трехкомпонентный вектор, содержащий приблизительные значения параметров a,b и c, входящих в аппроксимирующую функцию. Неправильный выбор элементов вектора vg может привести к неудовлетворительному результату регрессии. В MathCAD существуют средства для проведения регрессии самого общего вида. Это означает, что можно использовать любые функции в качестве аппроксимирующих и находить оптимальные значения любых их параметров, как линейных, так и нелинейных. В том случае, если регрессионная функция является линейной по всем параметрам, т.е. представляет линейную комбинацию жестко заданных функций, провести регрессию можно с помощью встроенной функции linfit(vx,vy,F). Аргумент F – это векторная функция, из элементов которой должна быть построена линейная комбинация, наилучшим образом аппроксимирующая заданную последовательность точек. Результатом работы функции linfit является вектор линейных коэффициентов. Каждый элемент этого вектора – коэффициент при функции, стоящей на соответствующем месте в векторе F. Таким образом, для того чтобы получить регрессионную функцию, достаточно скалярно перемножить эти два вектора.

Excel располагает средствами, позволяющими прогнозировать процессы. Задача аппроксимации возникает в случае необходимости аналитически описать явления, имеющие место в жизни и заданные в виде таблиц, содержащих значения аргумента (аргументов) и функции. Если зависимость удается найти, можно сделать прогноз о поведении исследуемой системы в будущем и, возможно, выбрать оптимальное направление ее развития. Такая аналитическая функция (называемая еще трендом) может иметь разный вид и разный уровень сложности в зависимости от сложности системы и желаемой точности представления.
10.1. Линейная регрессия
Самый простой и популярной является аппроксимация прямой линией – линейная регрессия.
Пусть мы имеем фактическую информацию об уровнях прибыли Y в зависимости от размера X капиталовложений – Y(X). На рис. 10.1-1 показаны четыре такие точки М(Y,X). Пусть также у нас имеются основания предполагать, что зависимость эта линейная, т.е. имеет вид Y=А+ВX. Если бы нам удалось найти коэффициенты A и B и по ним построить прямую (например, такую, как на рисунке), в дальнейшем мы могли бы сделать осознанные предположения о динамике бизнеса и возможном коммерческом состоянии предприятия в будущем. Очевидно, что нас бы устроила прямая, находящаяся как можно ближе к известным точкам М(Y,X), т.е. имеющая минимальную сумму отклонений или сумму ошибок (на рисунке отклонения показаны пунктирными линиями). Известно, что существует только одна такая прямая.

Для решения этой задачи используют метод наименьших квадратов ошибок. Разность (ошибка) между известным значением Y1 точки М1(Y1,X1) и значением Y(X1), вычисленным по уравнению прямой для того же значения X1, составит
D1 = Y1 – A – B X1.
Такая же разность
для X=X2 составит D2 = Y2 – A – B X2;
для X=X3 D3 = Y3 – A – B X3;
и для X=X4 D4 = Y4 – A – B X4.
Запишем выражение для суммы квадратов этих ошибок
Ф(A,В)=(Y1–A–B X1) 2 +(Y2–A–B X2) 2 +(Y3–A–B X3) 2 +(Y4–A–B X4) 2
или сокращенно Ф(B,A) = å(Yi – A – BXi) 2 .
Здесь нам известны все X и Y и неизвестны коэффициенты A и B. Проведем искомую прямую так (т.е. выберем A и B такими), чтобы эта сумма квадратов ошибок Ф(A,B) была минимальной. Условиями минимальности являются известные соотношения
Выведем эти выражения (индексы при знаке суммы опускаем):
¶[å(Yi–A–B Xi) 2 ]/¶A = å(Yi–A–B Xi)(–1)
¶[å(Yi–A–B Xi) 2 ]/¶B = å(Yi–A–B Xi)(–Xi).
Преобразуем полученные формулы и приравняем их нулю
По территориям региона приводятся данные за 200Х г.
Метод аппроксимации в Microsoft Excel

Среди различных методов прогнозирования нельзя не выделить аппроксимацию. С её помощью можно производить приблизительные подсчеты и вычислять планируемые показатели, путем замены исходных объектов на более простые. В Экселе тоже существует возможность использования данного метода для прогнозирования и анализа. Давайте рассмотрим, как этот метод можно применить в указанной программе встроенными инструментами.
Выполнение аппроксимации
Наименование данного метода происходит от латинского слова proxima – «ближайшая» Именно приближение путем упрощения и сглаживания известных показателей, выстраивание их в тенденцию и является его основой. Но данный метод можно использовать не только для прогнозирования, но и для исследования уже имеющихся результатов. Ведь аппроксимация является, по сути, упрощением исходных данных, а упрощенный вариант исследовать легче.
Главный инструмент, с помощью которого проводится сглаживания в Excel – это построение линии тренда. Суть состоит в том, что на основе уже имеющихся показателей достраивается график функции на будущие периоды. Основное предназначение линии тренда, как не трудно догадаться, это составление прогнозов или выявление общей тенденции.
Но она может быть построена с применением одного из пяти видов аппроксимации:
- Линейной;
- Экспоненциальной;
- Логарифмической;
- Полиномиальной;
- Степенной.
Рассмотрим каждый из вариантов более подробно в отдельности.
Способ 1: линейное сглаживание
Прежде всего, давайте рассмотрим самый простой вариант аппроксимации, а именно с помощью линейной функции. На нем мы остановимся подробнее всего, так как изложим общие моменты характерные и для других способов, а именно построение графика и некоторые другие нюансы, на которых при рассмотрении последующих вариантов уже останавливаться не будем.
Прежде всего, построим график, на основании которого будем проводить процедуру сглаживания. Для построения графика возьмем таблицу, в которой помесячно указана себестоимость единицы продукции, производимой предприятием, и соответствующая прибыль в данном периоде. Графическая функция, которую мы построим, будет отображать зависимость увеличения прибыли от уменьшения себестоимости продукции.
-
Для построения графика, прежде всего, выделяем столбцы «Себестоимость единицы продукции» и «Прибыль». После этого перемещаемся во вкладку «Вставка». Далее на ленте в блоке инструментов «Диаграммы» щелкаем по кнопке «Точечная». В открывшемся списке выбираем наименование «Точечная с гладкими кривыми и маркерами». Именно данный вид диаграмм наиболее подходит для работы с линией тренда, а значит, и для применения метода аппроксимации в Excel.
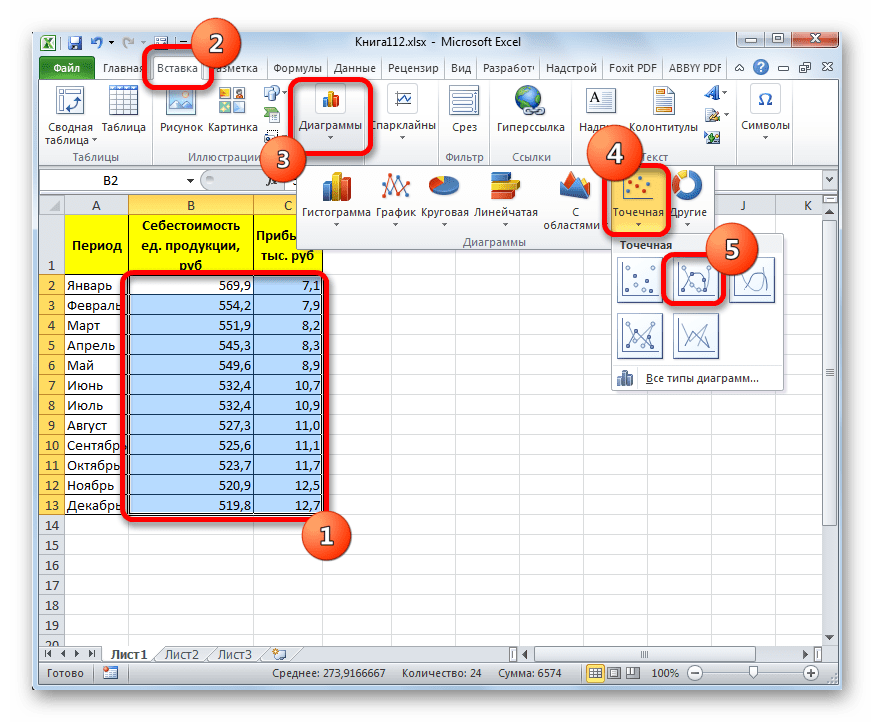
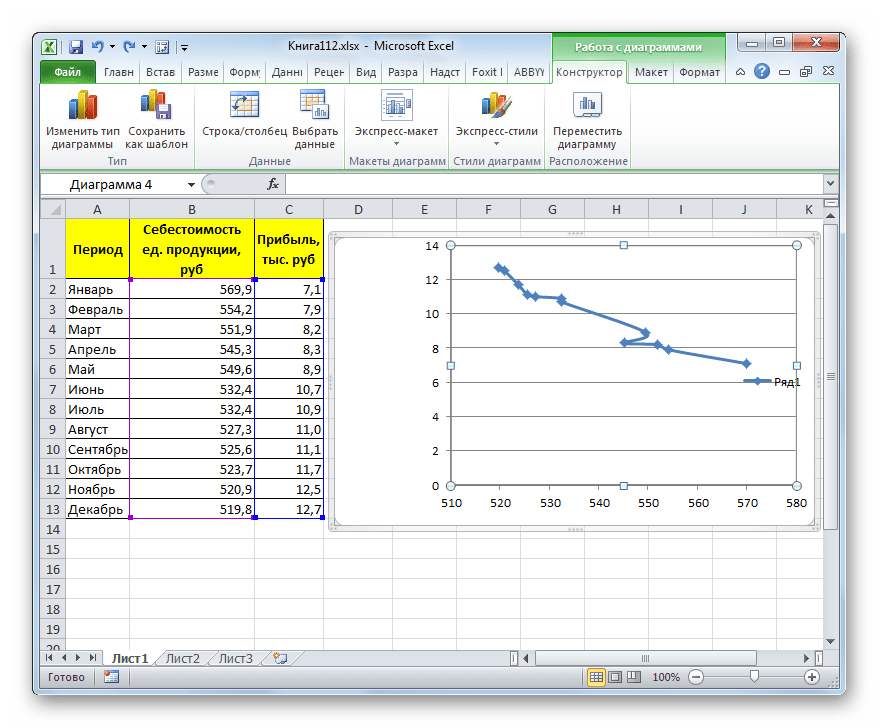
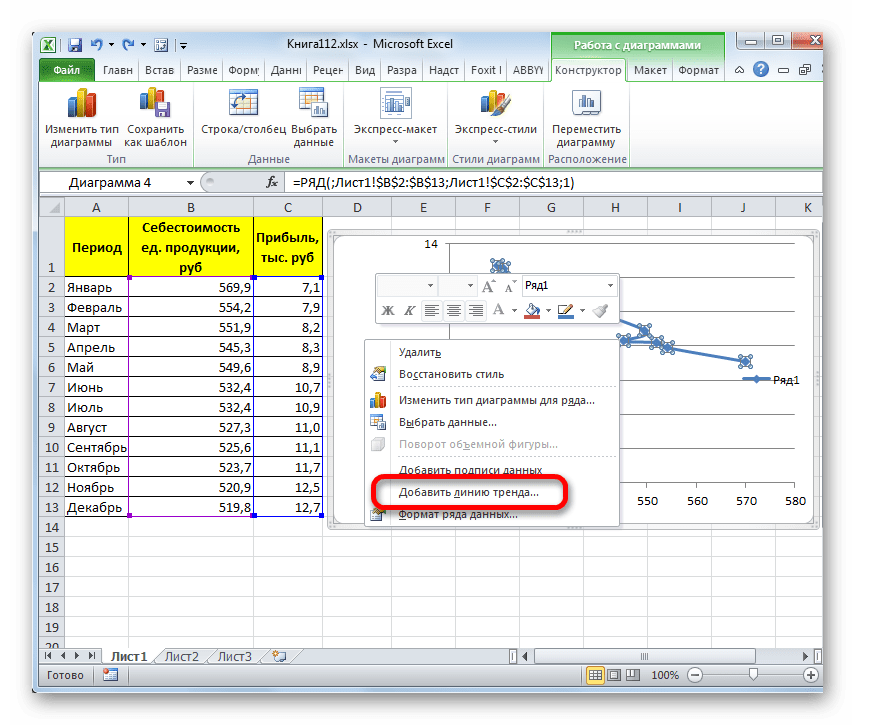
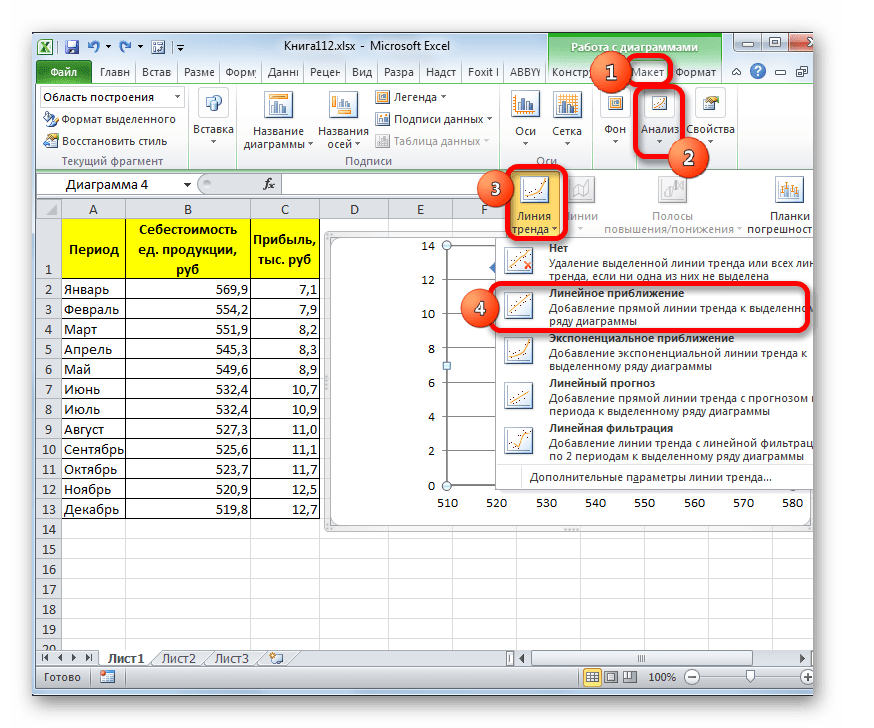
Существует ещё один вариант её добавления. В дополнительной группе вкладок на ленте «Работа с диаграммами» перемещаемся во вкладку «Макет». Далее в блоке инструментов «Анализ» щелкаем по кнопке «Линия тренда». Открывается список. Так как нам нужно применить линейную аппроксимацию, то из представленных позиций выбираем «Линейное приближение».
Если же вы выбрали все-таки первый вариант действий с добавлением через контекстное меню, то откроется окно формата.
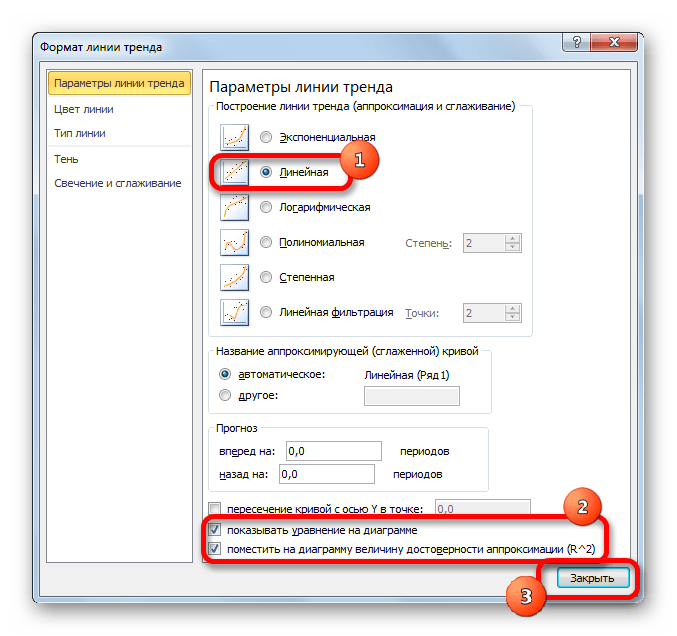
В блоке параметров «Построение линии тренда (аппроксимация и сглаживание)» устанавливаем переключатель в позицию «Линейная».
При желании можно установить галочку около позиции «Показывать уравнение на диаграмме». После этого на диаграмме будет отображаться уравнение сглаживающей функции.
Также в нашем случае для сравнения различных вариантов аппроксимации важно установить галочку около пункта «Поместить на диаграмму величину достоверной аппроксимации (R^2)». Данный показатель может варьироваться от до 1. Чем он выше, тем аппроксимация качественнее (достовернее). Считается, что при величине данного показателя 0,85 и выше сглаживание можно считать достоверным, а если показатель ниже, то – нет.
После того, как провели все вышеуказанные настройки. Жмем на кнопку «Закрыть», размещенную в нижней части окна.
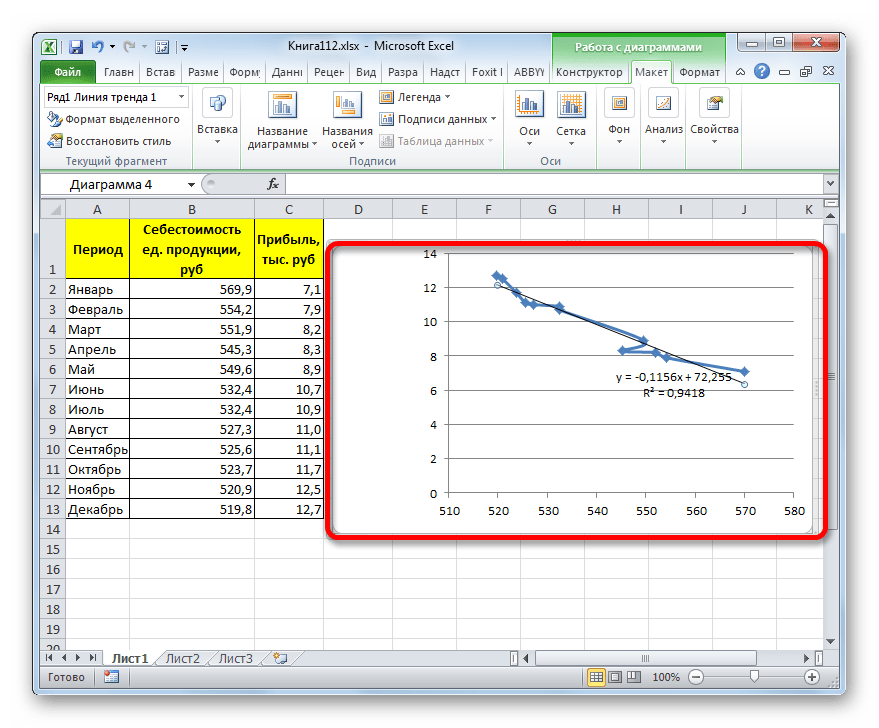
Сглаживание, которое используется в данном случае, описывается следующей формулой:
В конкретно нашем случае формула принимает такой вид:
Величина достоверности аппроксимации у нас равна 0,9418, что является довольно приемлемым итогом, характеризующим сглаживание, как достоверное.
Способ 2: экспоненциальная аппроксимация
Теперь давайте рассмотрим экспоненциальный тип аппроксимации в Эксель.
-
Для того, чтобы изменить тип линии тренда, выделяем её кликом правой кнопки мыши и в раскрывшемся меню выбираем пункт «Формат линии тренда…».
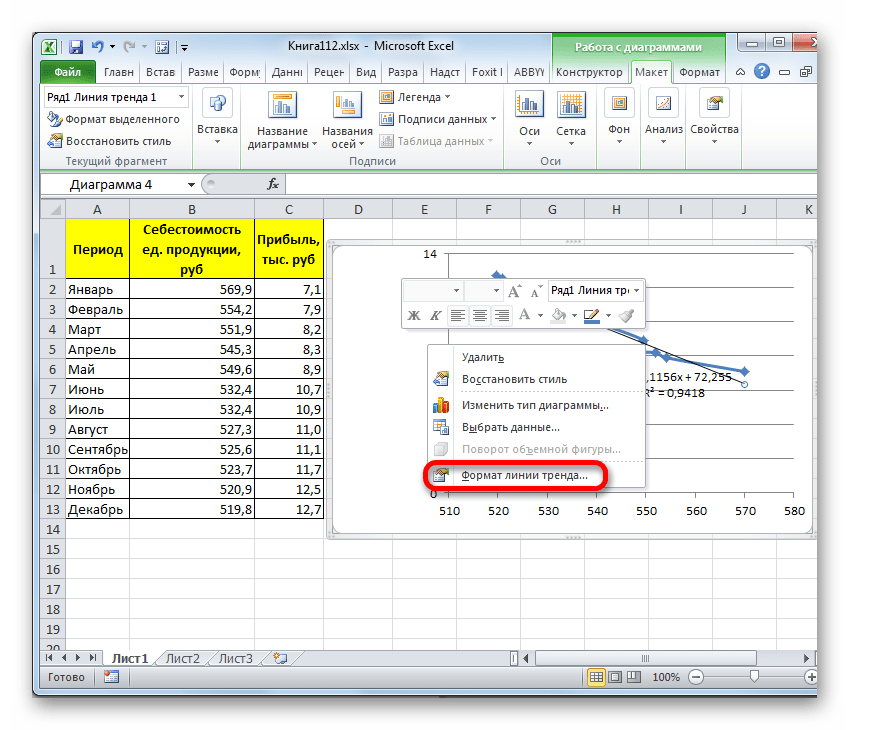
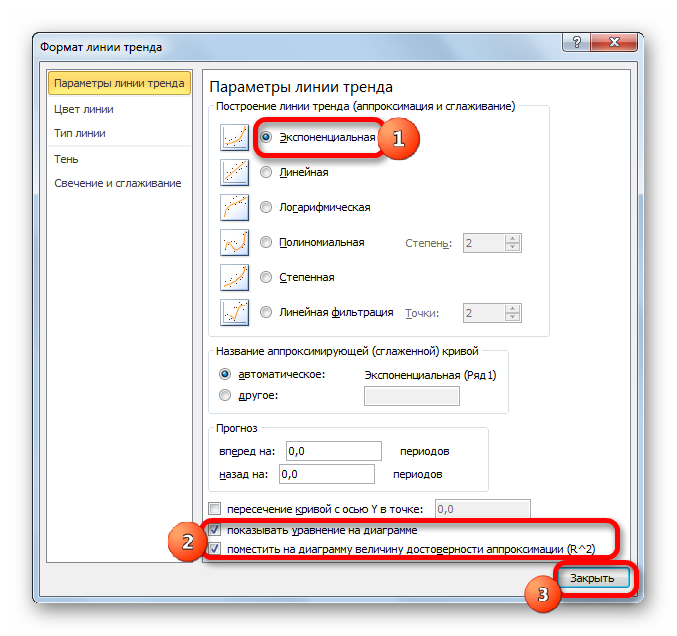
После этого запускается уже знакомое нам окно формата. В блоке выбора типа аппроксимации устанавливаем переключатель в положение «Экспоненциальная». Остальные настройки оставим такими же, как и в первом случае. Щелкаем по кнопке «Закрыть».
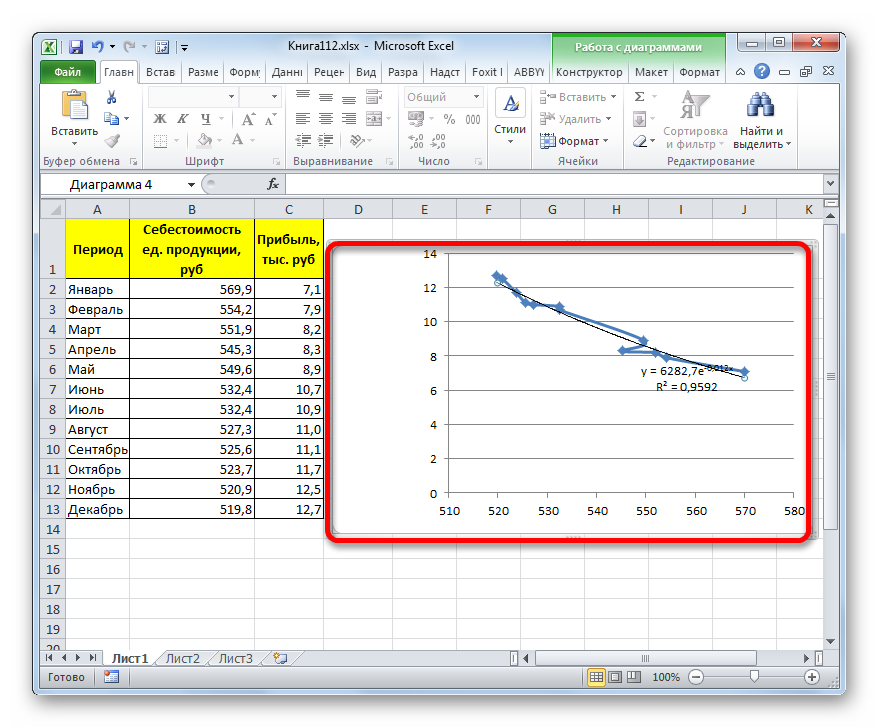
Общий вид функции сглаживания при этом такой:
где e – это основание натурального логарифма.
В конкретно нашем случае формула приняла следующую форму:
Способ 3: логарифмическое сглаживание
Теперь настала очередь рассмотреть метод логарифмической аппроксимации.
-
Тем же способом, что и в предыдущий раз через контекстное меню запускаем окно формата линии тренда. Устанавливаем переключатель в позицию «Логарифмическая» и жмем на кнопку «Закрыть».
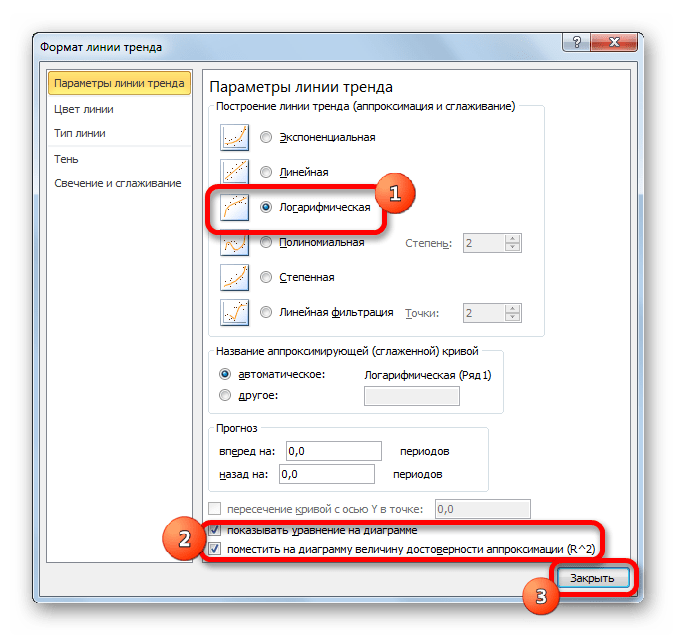
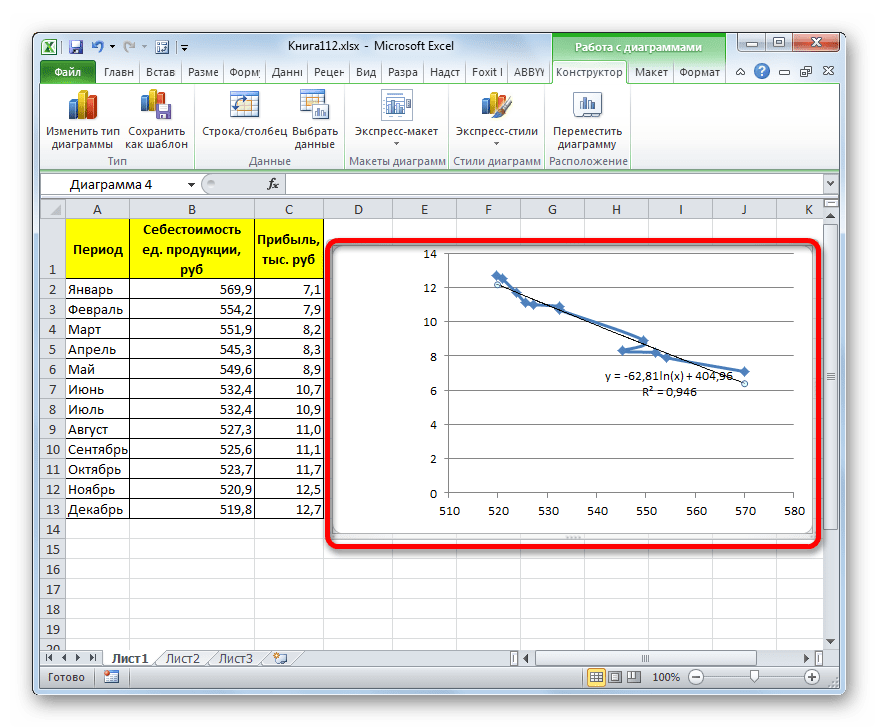
В общем виде формула сглаживания выглядит так:
где ln – это величина натурального логарифма. Отсюда и наименование метода.
В нашем случае формула принимает следующий вид:
Способ 4: полиномиальное сглаживание
Настал черед рассмотреть метод полиномиального сглаживания.
-
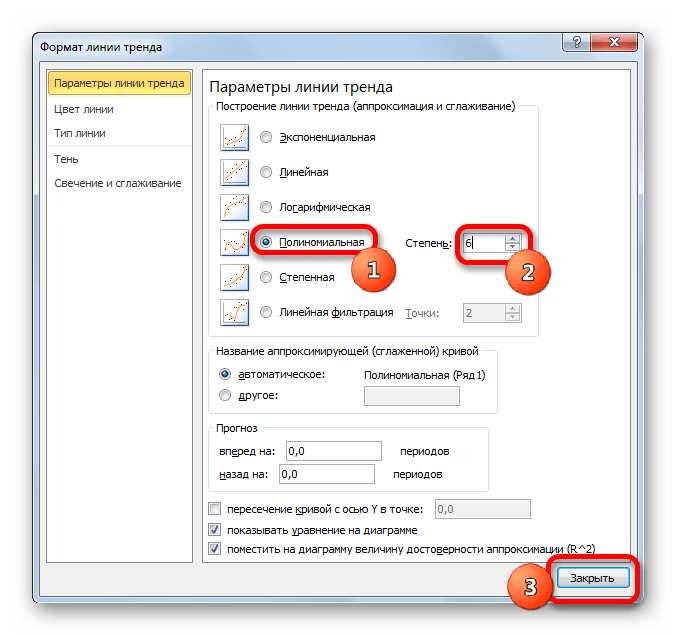
Переходим в окно формата линии тренда, как уже делали не раз. В блоке «Построение линии тренда» устанавливаем переключатель в позицию «Полиномиальная». Справа от данного пункта расположено поле «Степень». При выборе значения «Полиномиальная» оно становится активным. Здесь можно указать любое степенное значение от 2 (установлено по умолчанию) до 6. Данный показатель определяет число максимумов и минимумов функции. При установке полинома второй степени описывается только один максимум, а при установке полинома шестой степени может быть описано до пяти максимумов. Для начала оставим настройки по умолчанию, то есть, укажем вторую степень. Остальные настройки оставляем такими же, какими мы выставляли их в предыдущих способах. Жмем на кнопку «Закрыть».
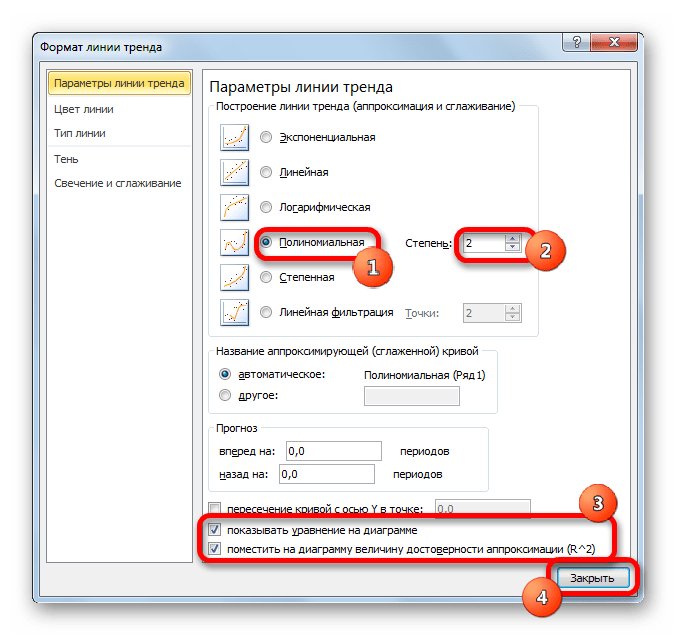
Линия тренда с использованием данного метода построена. Как видим, она ещё более изогнута, чем при использовании экспоненциальной аппроксимации. Уровень достоверности выше, чем при любом из использованных ранее способов, и составляет 0,9724.
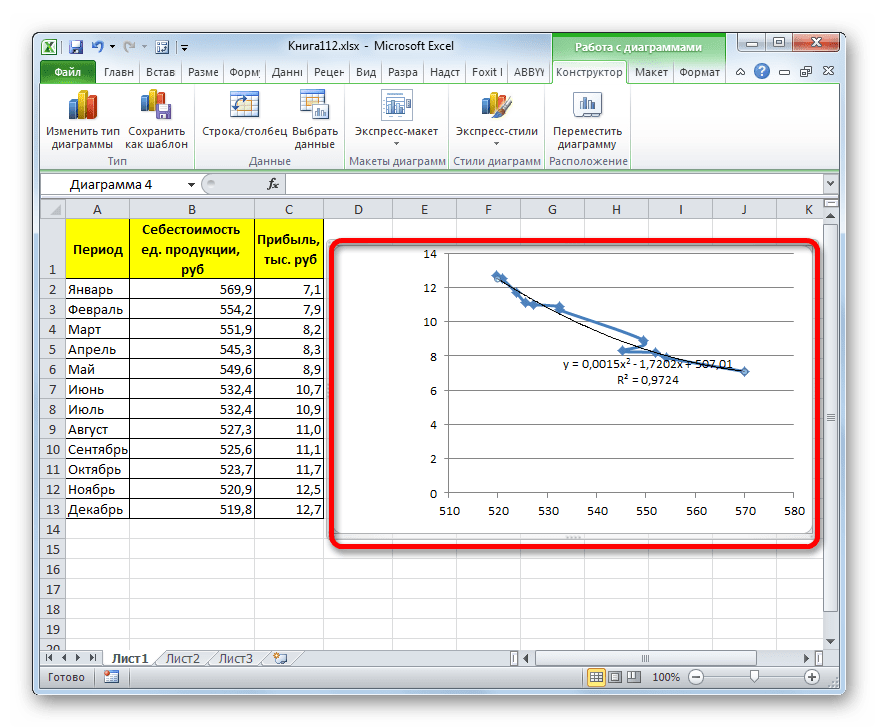
Данный метод наиболее успешно можно применять в том случае, если данные носят постоянно изменчивый характер. Функция, описывающая данный вид сглаживания, выглядит таким образом:
В нашем случае формула приняла такой вид:
y=0,0015*x^2-1,7202*x+507,01
Теперь давайте изменим степень полиномов, чтобы увидеть, будет ли отличаться результат. Возвращаемся в окно формата. Тип аппроксимации оставляем полиномиальным, но напротив него в окне степени устанавливаем максимально возможное значение – 6.
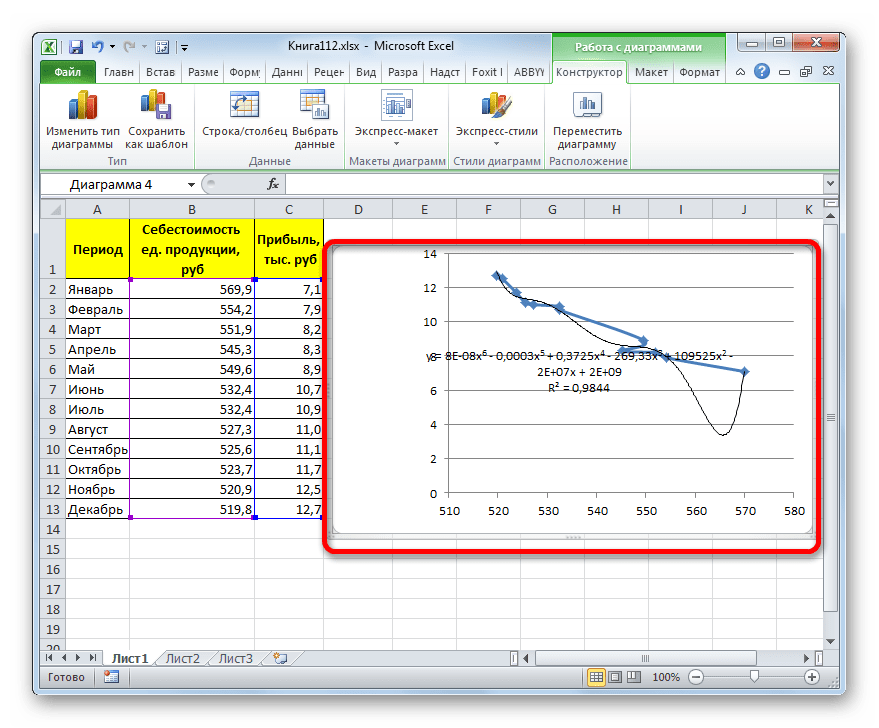
Формула, которая описывает данный тип сглаживания, приняла следующий вид:
Способ 5: степенное сглаживание
В завершении рассмотрим метод степенной аппроксимации в Excel.
-
Перемещаемся в окно «Формат линии тренда». Устанавливаем переключатель вида сглаживания в позицию «Степенная». Показ уравнения и уровня достоверности, как всегда, оставляем включенными. Жмем на кнопку «Закрыть».
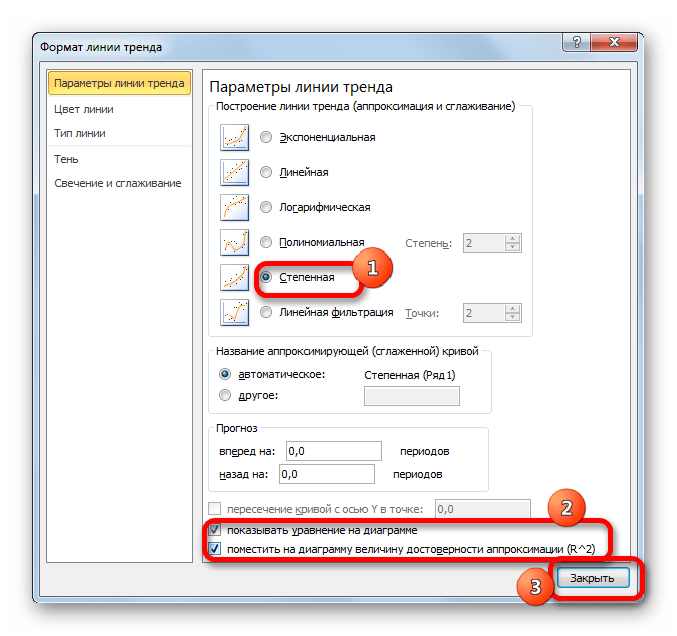
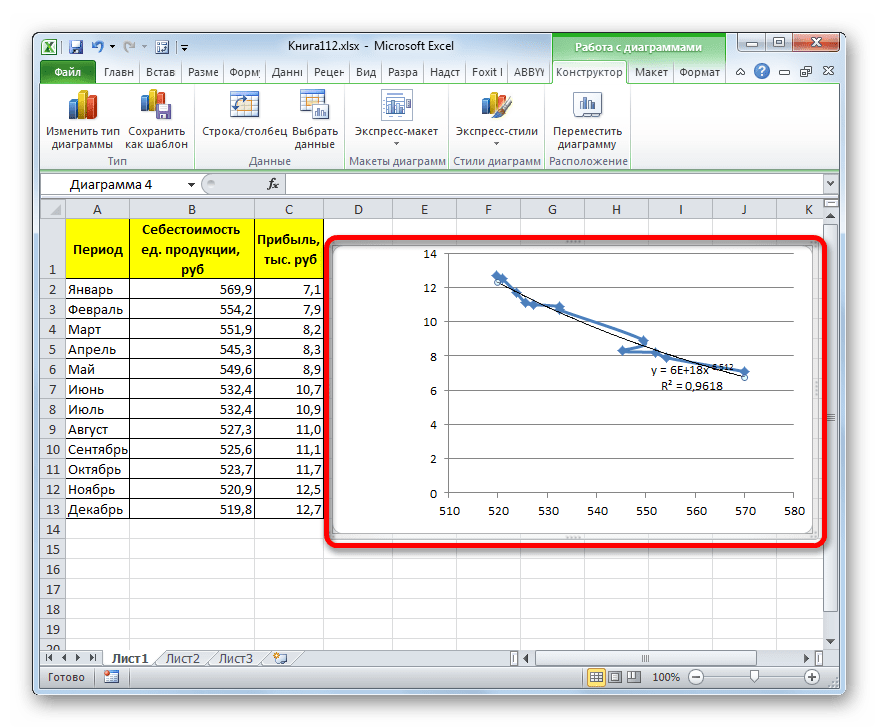
Данный способ эффективно используется в случаях интенсивного изменения данных функции. Важно учесть, что этот вариант применим только при условии, что функция и аргумент не принимают отрицательных или нулевых значений.
Общая формула, описывающая данный метод имеет такой вид:
В конкретно нашем случае она выглядит так:
Как видим, при использовании конкретных данных, которые мы применяли для примера, наибольший уровень достоверности показал метод полиномиальной аппроксимации с полиномом в шестой степени (0,9844), наименьший уровень достоверности у линейного метода (0,9418). Но это совсем не значит, что такая же тенденция будет при использовании других примеров. Нет, уровень эффективности у приведенных выше методов может значительно отличаться, в зависимости от конкретного вида функции, для которой будет строиться линия тренда. Поэтому, если для этой функции выбранный метод наиболее эффективен, то это совсем не означает, что он также будет оптимальным и в другой ситуации.
Если вы пока не можете сразу определить, основываясь на вышеприведенных рекомендациях, какой вид аппроксимации подойдет конкретно в вашем случае, то есть смысл попробовать все методы. После построения линии тренда и просмотра её уровня достоверности можно будет выбрать оптимальный вариант.
Отблагодарите автора, поделитесь статьей в социальных сетях.
Источники:
http://lugatrans.ru/oshibka-approksimacii-eksel-kak-sdelat-aproksimaciyu-v/
http://lumpics.ru/approximation-in-excel/